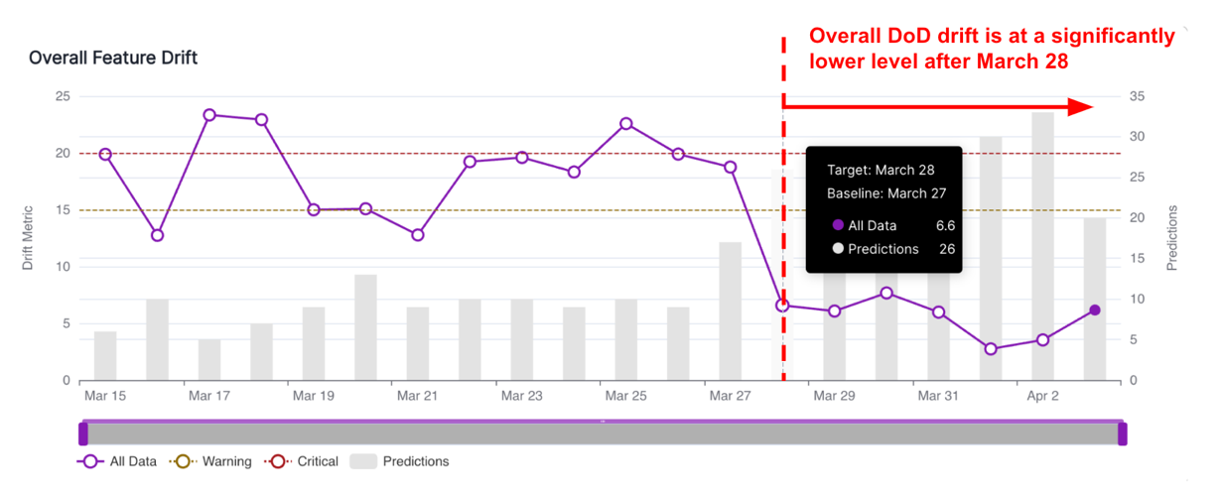
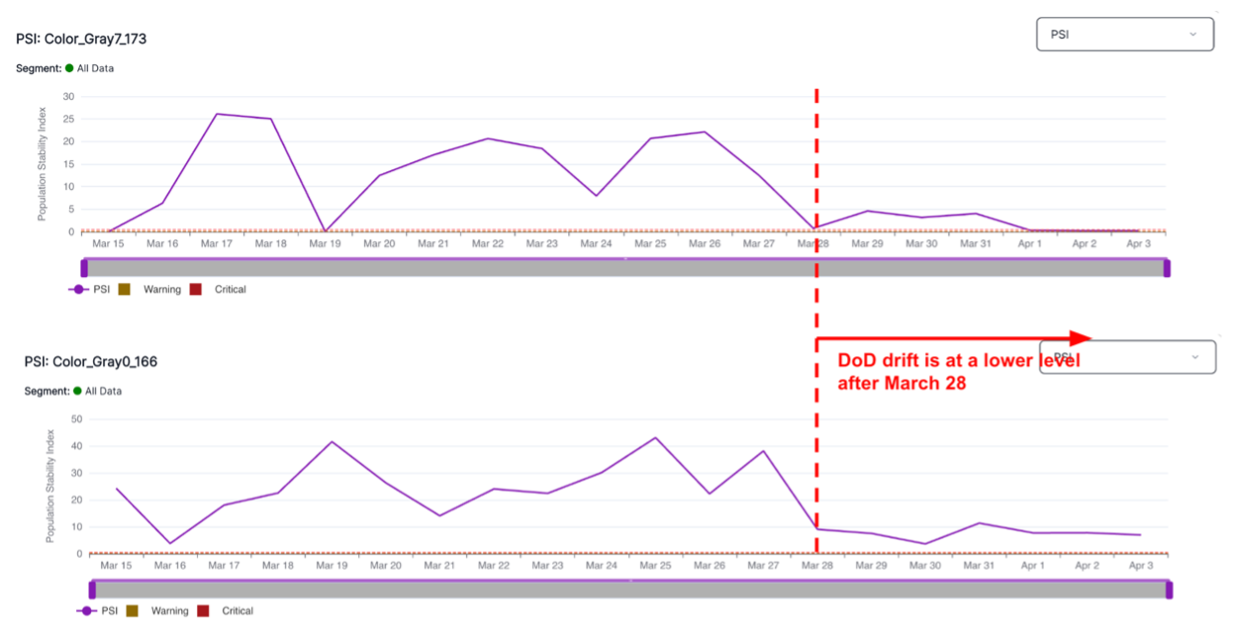
A Shared Understanding of Terms Can Be the Lynchpin for Successful ML Operations

A Glossary of Terms for Monitoring Model Drift and Performance
In the world of machine learning and predictive modeling, it is crucial to monitor the performance of models over time. One key aspect of this monitoring is to detect and understand drift, which refers to changes in the value distribution of various features and predictions. To navigate this field effectively, it is essential to understand the terminology associated with model monitoring.In our work with customers, we have seen that teams are often distributed, siloed by organizational structures, can vary in terms of who “owns” monitoring once a model is in production (sometimes it’s the data scientist, sometimes it’s the ML operations team or ML Engineer and so on). Here we attempt to provide a glossary of terms related to monitoring model drift and performance, to help teams navigate the challenges and solutions, in order to drive successful ML Operations.
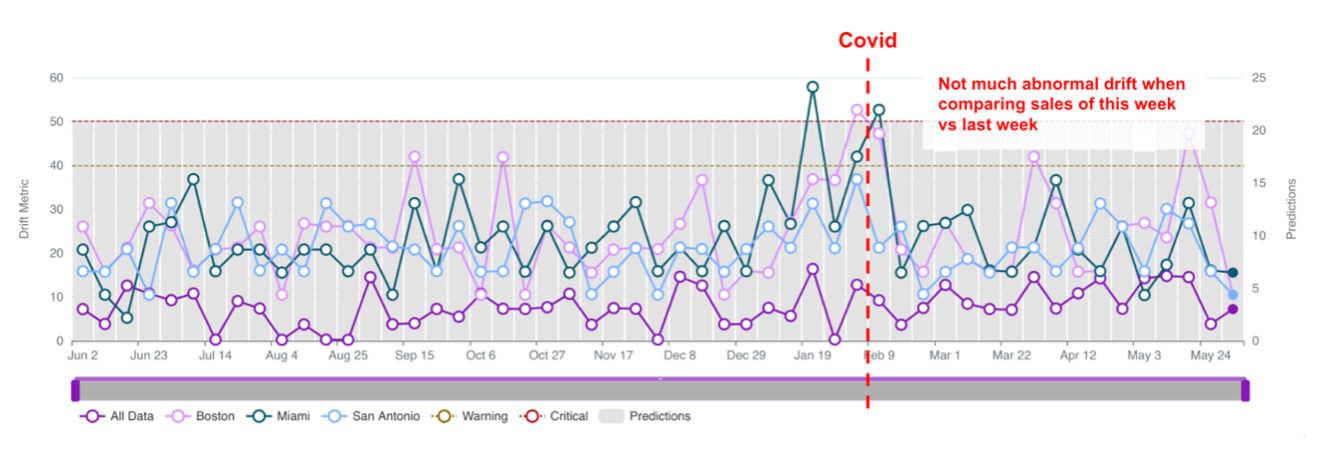
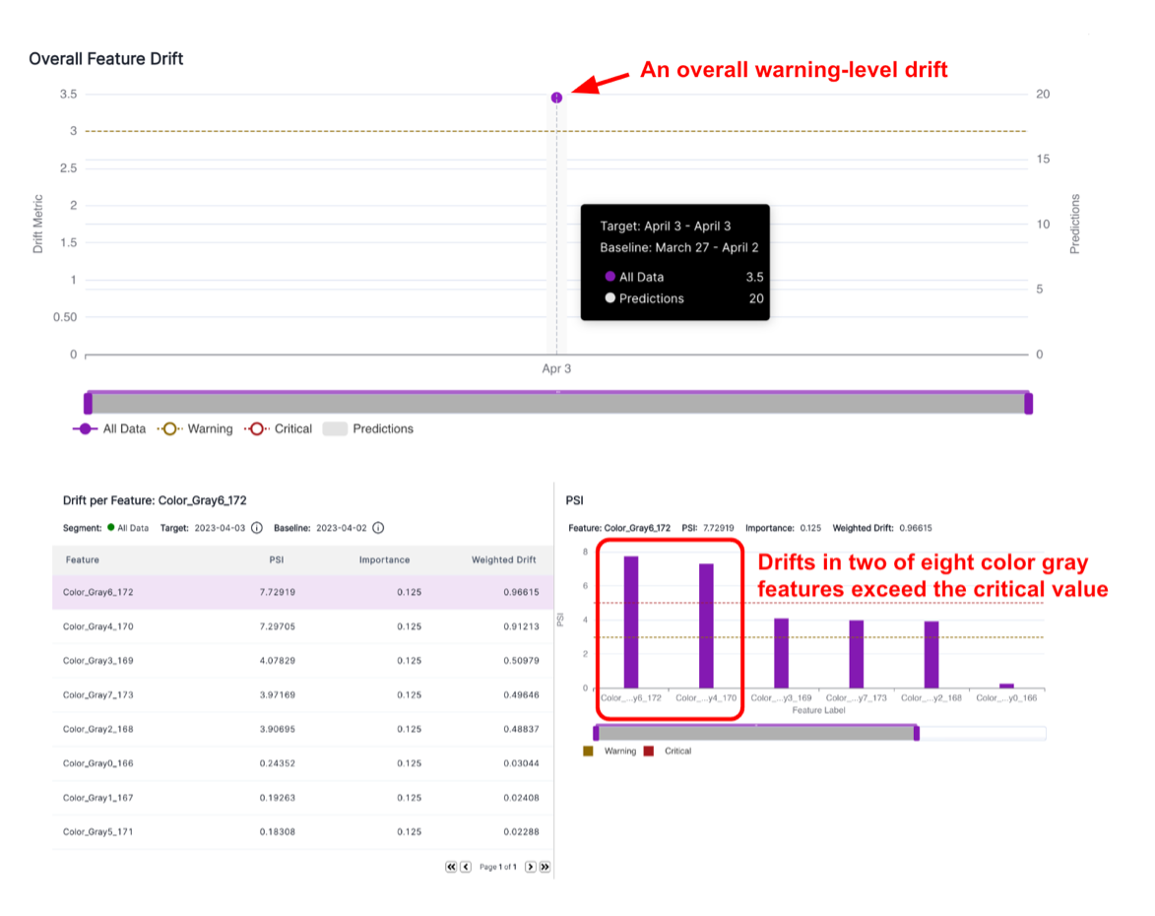
| Alert: | An alert is an informational flag that indicates when drift has reached a pre-defined threshold in a policy. Alerts come in different levels, including critical (requiring immediate attention) and warning (needing attention). |
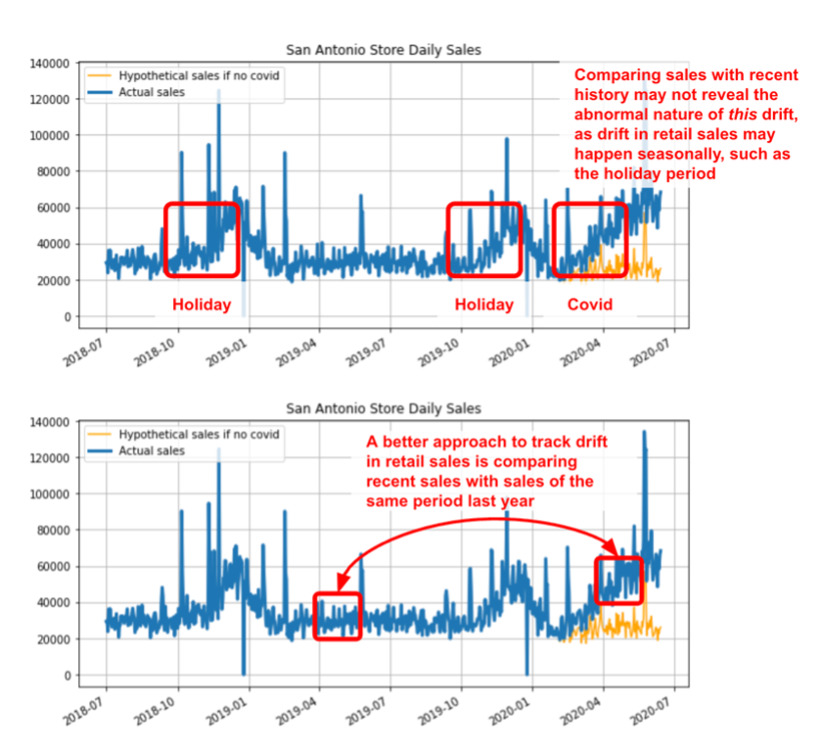
| Baseline window: | The baseline window serves as a reference point for comparing metrics when monitoring model performance or drift. Baselines can be different types of data, such as training data or previous time periods of production data, like the prior day, the same weekdays of the last three weeks, prior week, prior month, prior quarters, and more. |
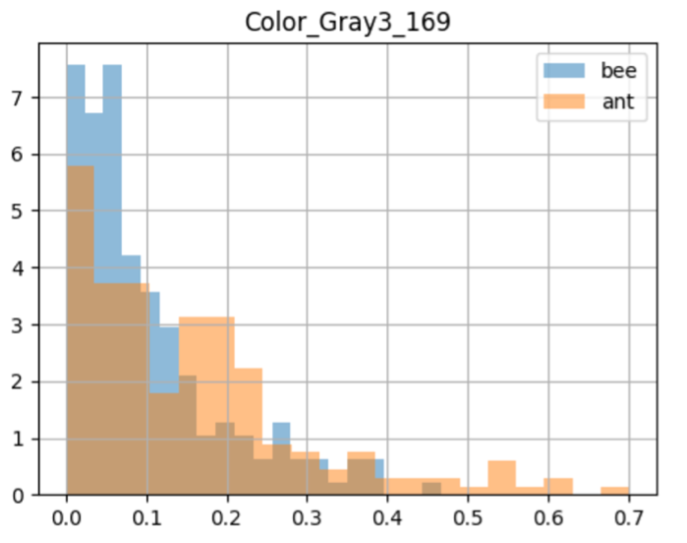
| Custom binning: | Custom binning allows users to define their own histogram bin edges. It involves creating a user-defined list of bin edges to group data into specific ranges. Any data falling outside these bins are grouped into the nearest bin based on proximity. By default, a tool like VIANOPS uses baseline decile binning. |
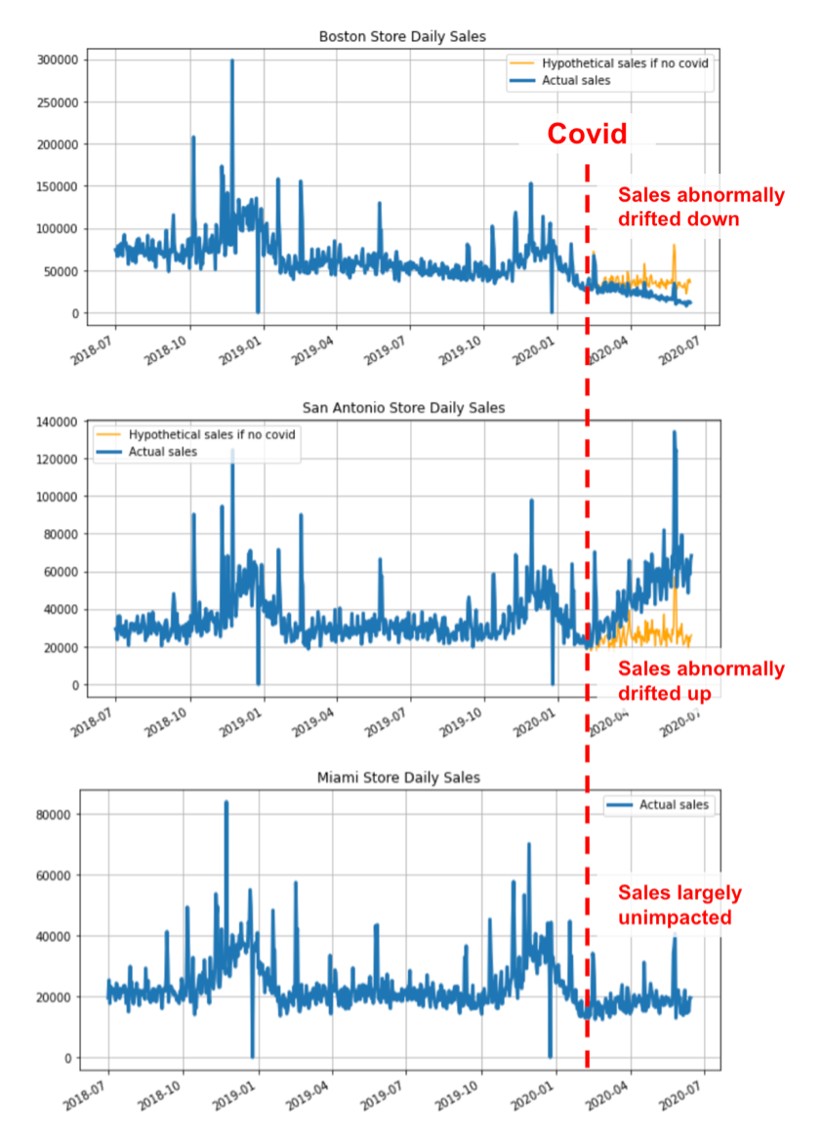
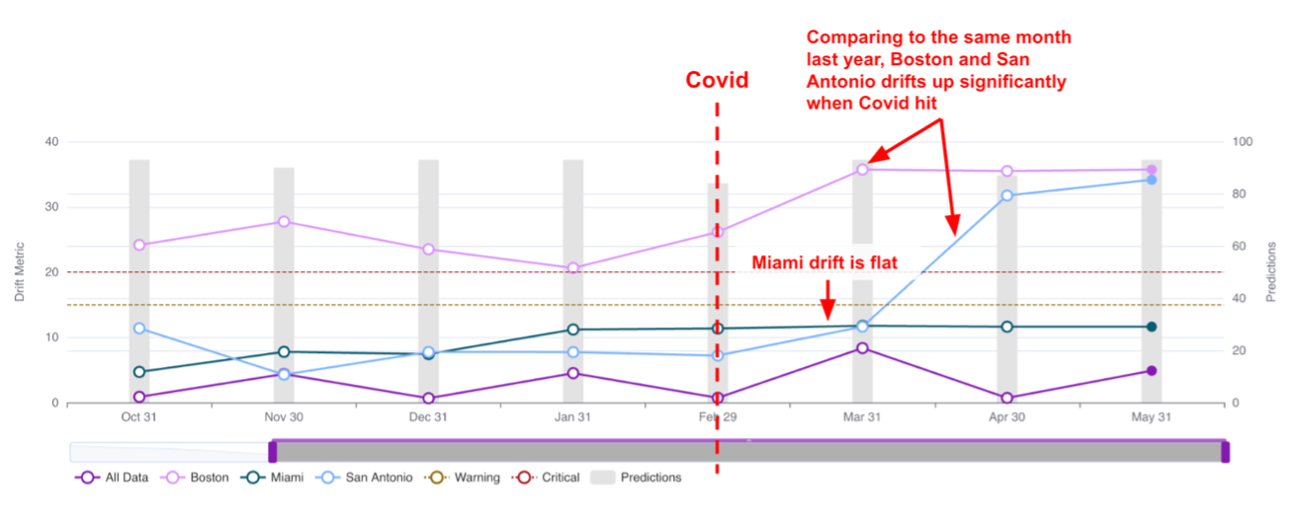
| Drift: | Drift refers to changes in the value distribution of the target window and baseline window for an input feature or prediction output. It can manifest as changes in the performance of a model or shifts in the distribution of specific features. |
| Feature: | A feature is an input to a model that represents a measurable piece of data. Features can include variables like distance, fare, location, age, and more. Models typically have tens to thousands of features. |
| Feature drift: | Feature drift refers to changes in the value distribution of a specific feature in the target time window compared to the baseline window. It quantifies the changes observed in a feature over time, such as the drift in trip_distance this month compared to the same month last year. |
| Ground truth: | Ground truth refers to the real value or outcome of an event. It serves as a reference point for evaluating the accuracy and performance of predictive models. |
| Hotspot: | A hotspot is a specific area or region within a dataset where an event occurs more frequently or exhibits higher values compared to the surrounding areas. Hotspots highlight areas of interest and potential patterns in the data. |
| Hotspot analysis: | Hotspot analysis is a technique used to identify hotspots within a dataset. It helps uncover areas where certain events or values are significantly different from the norm. |
| Metric: | A metric is a measure used to evaluate policies and model performance. In the context of monitoring model drift and performance, there are different types of metrics, including distance-based drift metrics (e.g., PSI, JSD) and performance metrics for classification and regression tasks. |
| Model: | A model is a predictive algorithm or system used to make predictions based on input data. Models can be binary classification, multi-class classification, regression, ranking, recommendation, or other types, and different model types have specific metrics to measure their performance. |
| Performance drift: | Performance drift refers to changes in the performance metrics of a model between the target window and the baseline window. It quantifies shifts in model performance over time, such as changes in accuracy, precision, recall, or other relevant metrics. |
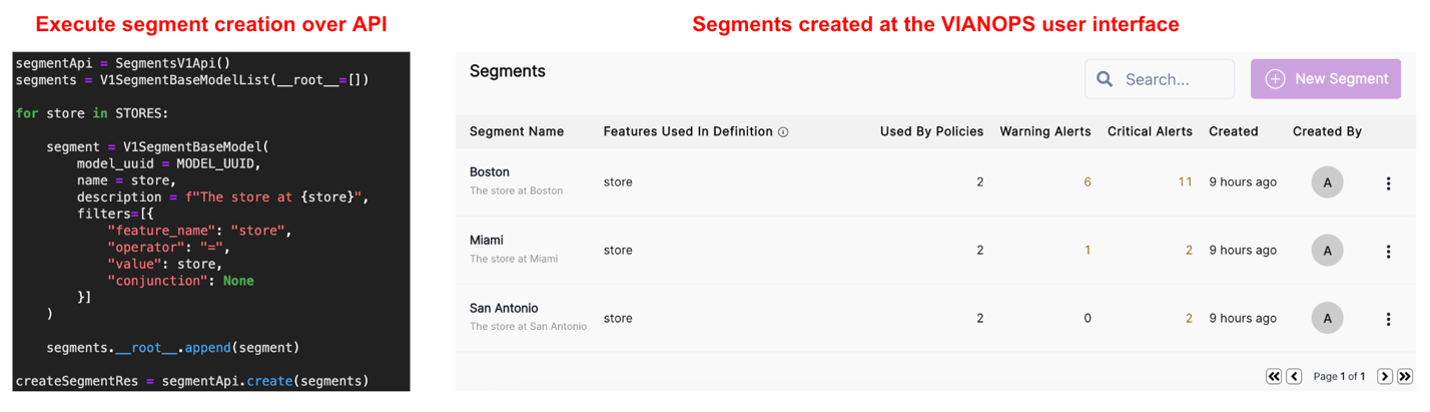
| Policy: | A policy is a set of rules that define a process for monitoring and alerting users about drift. Policies can be created to monitor feature drift, prediction drift, or performance drift. They include specifications such as target and baseline windows, drift metrics, alert thresholds, schedules, selected segments, and features. |
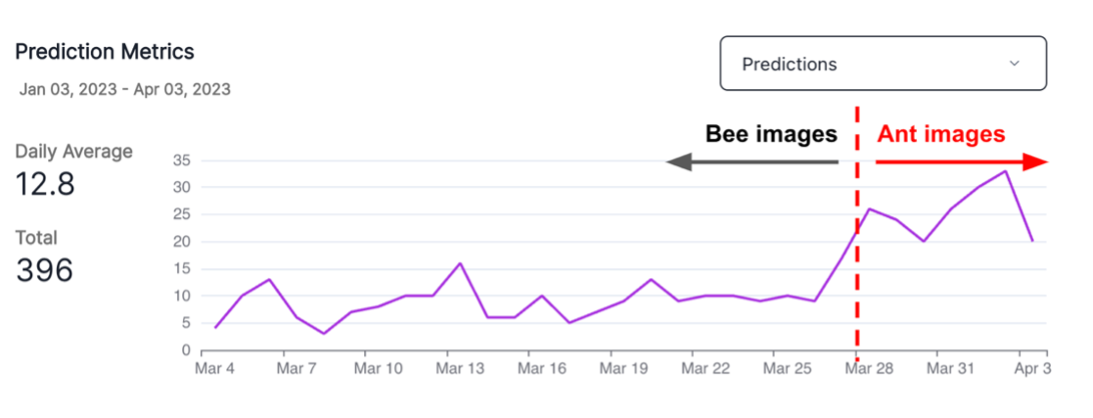
| Prediction: | A prediction is the output of a model. The nature of predictions depends on the type of model used. For example, a binary classification model may output either 0 or 1, while a regression model produces numeric values. |
| Prediction drift: | Prediction drift refers to changes in the distribution of predictions made by a model between the target window and the baseline window. It assesses shifts in the model’s predictions over time and helps identify potential issues or changes in the underlying data. |
| Project: | A project refers to a collection of models that serve a common purpose. Grouping models within a project facilitates organization and management of related models. |
| Segment: | A segment is a subsection of a dataset used to narrow the scope and uncover patterns that may be occurring only within specific sections of the population. Segments help analyze and compare performance and drift across different subsets of data, such as specific locations, age groups, or other relevant criteria. |
| Schedule: | A schedule determines how frequently a policy runs. It can be set to run daily, weekly on a specific weekday, monthly on a specific day, or other customizable intervals. |
| Target window: | The target window refers to the timeframe of data being monitored. It can be defined as the last 24 hours, week-to-date, month-to-date, or other relevant periods, depending on the monitoring requirements. |
| Threshold: | A threshold determines the severity level at which alerts or other actions are triggered. VIANOPS, for example, defines two levels of thresholds: Critical, which signifies severe issues requiring immediate attention, and Warning, which indicates issues that are less critical but still merit attention. |
| Value distribution: | Value distribution refers to the frequency of specific values falling into different bins or value ranges for a feature during the target or baseline window. Tools like VIANOPS allow users to customize how value ranges are grouped for easy interpretation in a business context. By default, VIANOPS groups continuous feature values into 10 bins, while categorical features use the categories as bins. |
In our conversations with customers, sometimes the most challenging part is ensuring everyone is on the same page about the goals, challenges and desired outcomes in monitoring models once deployed, especially in highly distributed teams that want to leverage best practices, or when models are handed off from development to production stages. Finding common terminology can help teams drive enhanced collaboration and identify the solutions that ensure the ongoing reliability and accuracy of their predictive models.
Running high-scale model monitoring, or just getting started? VIANOPS can help – we would love to connect.